前言
小程序,作为新一代的应用开发方式,虽然在业务上已经证明了巨大的价值,但是在开发者友好性上却非常的差,例如框架难用,调试困难,跨平台兼容性差。本文便是在尝试提高针对视图的开发者友好性和兼容性,同时进一步提升性能。
为了能够更好的理解本文,需要您最好了解以下内容:
有小程序相关的经验,能够理解基本小程序的架构、基本的框架使用方式、主流的跨端三方框架等
有前端相关的经验,能够理解什么是 DOM 接口,以及如何操作 DOM 接口
本文将不再赘述过多的基础概念内容。
背景
目前本人任职飞书开放平台小程序组,负责小程序相关的运行时的工作内容。由于飞书对小程序有着一些特殊的需求:
飞书大量官方应用都是通过小程序承载的,这些应用对运行体验和开发效率有着远比外界更高的要求。而且由于是官方应用,且只服务于飞书,所以他们对于小程序的跨端兼容性要求并不高。这也给了我们更大的灵活性去设计更好的方案。
飞书是一个面向全球 B 端的市场,先不论国内是否每个 B 端企业都能有精力去开发小程序,单论海外市场对小程序的认知就非常浅薄。所以如何尽可能的降低小程序的认知学习门槛,降低接入成本,就显得尤为重要。在国内可以通过类似于 Taro 的框架,但是海外这部分的学习成本依旧很高,所以需要有新的方式去降低这部分的成本。
正是因为如此,我们这边决定不再以兼容社区小程序的方案为首要目标,而是转为提高开发者的开发体验和运行性能为主目标去进行设计和优化。
现有架构的「病区」
小程序在诞生之后,其实做了很多的设定,有的设定是合适的,但更多的设定在逐渐的发展过程中变得不再合适,而后人却依旧沿着这个思路和方向去做。接下来,让我们重新思考一下这些设定:
为什么会诞生 XXML 的视图开发方案?
XXML在这里是对通过模板开发小程序的一种开发范式(也可以叫开发框架或者 DSL)的统称。因为不同宿主内对应的模板文件的后缀不同,但都有ML而因此得名。例如微信是.wxml,支付宝是.axml,而飞书和抖音则为.ttml。
在我的认知中,小程序最开始并不是为资深的前端开发而设计的,相反,他是为了客户端乃至一些没有开发经验的人所设计。
所以借鉴了 Vue 这类非常容易入门的社区框架,再结合上小程序自身的需求所定制了一套 DSL。这套 DSL 针对从来没有写过前端的人来说,确实算是非常友好的,几乎不需要学习就可以上手。
其实让开发者更容易的入门上手算是小程序最开始的目标。例如,一开始是不提供 CLI 工具只提供了可视化的 IDE。如果小程序的受众是不懂开发的人,那其实没问题。
但最终事与愿违,开发小程序最多的人其实就是资深的前端开发,在前端开发的视角来看,这套 DSL 可以用一坨屎来形容。而小程序又必须要要用这套 DSL 去开发,就导致每一个写过小程序的人必须吃一次这个屎。
XXML 会带来什么问题?
虽然以微信为首的厂商做了很多能力去补救,尽可能在保证较低入手门槛的情况下,不断丰富能力,提高对前端开发人员的友好程度。但最开始的设计就不是面向这部分人群,即使后面修补的再多也无济于事了。这其中所带来的的问题随着小程序的发展而愈发严重:
由于这套框架的实现是内置在基础库内,其能力和功能的实现必然有滞后性,同时灵活度差。一旦框架概念落后,开发者将不得不继续咬牙学习落后内容。
虽然最开始借鉴自 JS 和 Web,但最终却无法的很好的利用开源社区的能力,几乎所有都要重造轮子。国内已经发展了这么多年,社区才将将都造完稳定的轮子,如果将这一套推向海外,那成本根本无法估量。
规范缺乏一致性。由于 XXML 本身其实是一个业务开发框架,但又作为唯一开发方式,非常容易变得越来越臃肿和随意,可能一个实习生随便定出的接口都将会影响整个社区,能力的实现也缺乏一致性。例如
Page和Component的生命周期就非常不一样。为了解决 XXML 这些问题,降低开发者的开发成本,在社区中诞生了许许多多的三方跨端框架。导致开发小程序的人不仅仅要懂得如何写原生的 XXML,更要懂得如何使用这些跨端框架,学习成本陡增。
Taro 这类模拟一套 DOM 接口来嫁接社区框架的做法,最终会让运行架构变成
React => Taro DOM => TTML => DOM这种有点脱裤子放屁的方式。
小程序的视图开发一定要使用 XXML 么?
一个支持通用应用的宿主,可以提供一套它认为合适的模板 DSL 去生成渲染树,但一定也需要提供一套更加灵活的方式去生成渲染树。例如:
安卓默认使用 XML 作为模板,去渲染内容。但如果不满足使用,同时可以使用命令的操作方式去构建一个渲染树。iOS 也是用类似的逻辑
Flutter 定义了一套类似于 React 的 Weight 渲染框架。但依旧暴露了底层的 RenderObject 方便开发者绕过 Weight 直接去构建渲染树。
而小程序,却选择了只提供 XXML,并没有提供其他的方式。如果小程序面向的特定需求场景,这倒也无可厚非,可实际上小程序面向的却是通用需求场景。
于是飞书内部在思考,如果我们一定要再提供一套通用的 DSL,会是什么?React、Vue 这类前端框架么?如果提供了,又会面临和 XXML 类似的局面。
其实在 Web 领域中,早就给出了答案,那么就是 DOM。不管是 React 还是 Vue 还是其他的框架,底层都是基于 DOM 接口所存在的。如果我们能够在小程序提供一套底层的 DOM 接口,那么 XXML 所带来的问题是不是就全都迎刃而解了呢?
为什么之前不提供 DOM 接口?
当我们想明白这个点之后,其实就会更加好奇,为什么这么简单的想法为啥一开始乃至后续的人都没做过呢?
我猜测最开始不这么做的原因有这么几个,但我觉得都不是很成立,或者说在飞书的场景中很难成立(如果大家有不同的想法和意见,随时可以和我沟通交流)。
Q: 无法完整实现,成本高。
双线程无法实现完整的 DOM 接口,且在逻辑层实现一套 DOM 接口的成本过高。
确实,如果想要一比一的复刻 DOM 接口,有些依赖渲染能力的接口确实无法实现。但如果只是实现一套子集,能够满足主流框架的使用,那么成本和难度并不高。比如 Taro 就是这么做的,社区也证明了其可行性。
Q: 首屏性能差。
如果实现 DOM 接口,就必须要等待逻辑层完整渲染并操作完 DOM 接口之后,渲染层才能渲染,那么将失去双线程逻辑层和渲染层并行运行的优势。
我觉得这个是一个屁股决定脑袋的事情。在 90% 的场景中,渲染层就是需要等待逻辑层计算完毕之后才能渲染的。就像是你不能说为了前端页面首屏速度快,要求所有网站都用 SSR 吧。
另外,首屏其实分为 FP 和 TTI 的,和 SSR 场景类似,XXML 可以做到 FP 快,但是 TTI 并不如 DOM 快的。飞书场景更在乎的是 TTI 而非 FP,所以影响不大。
再说,用了 DOM 接口之后自然是有对应的优化策略和方式的。
Q: DOM 指令的通讯压力大。
如果采用 DOM 接口,那么逻辑层往渲染层发送的将是 DOM 指令,如果我要渲染 100 个普通的 view,这部分体积明显比直接发送 data 要大。
没错,某些场景下,DOM 指令的数量确实是会比 data 体积大。
但是在飞书的业务场景中,通常都会有着重度的逻辑以及大量国际化文案,这部分会导致 data 的体积飞涨。而且并不是所有的开发都有合理使用 data 的能力的,有些人就喜欢啥都往 data 里面塞,这更加会加剧其体积的膨胀。
所以对于飞书来说,这个的影响其实并不大。
Q: 觉得 TTML 就够用了
懂的都懂,不多说了
Q: 不希望对外认知上小程序就是前端,所以在一定程度上屏蔽了前端所用的东西。
我觉得这其实是微信小程序的烟雾弹,让大家觉得小程序技术很厉害,它底层是 Native 实现,只是借鉴了前端的一些概念而已。
但实际上缺恰恰相反,从设计开始,就是在 Web 上面打补丁实现的,只是借鉴了一点点 Native 中的概念。
所以如果相信了这个烟雾弹,那么才是将自己埋入深坑。
Q: 不希望利用 DOM 接口实现太多灵活的动态更新能力。
例如审核之后通过 API 更改 UI 界面。
这个也是我见过最多的说法了,也是最站不住脚的说法。
XXML 本身就无法避免动态更新,更别说 DOM 了。
Q: DOM 接口就不会有实现上的兼容问题了么?
这是个好问题,虽然 DOM 接口本身是有标准的,但实现上其实各家都会遇见的不一样。
这个自然没有完美的解决方案,但是我觉得以兼容主流框架而不是提供完整兼容的 DOM 接口为目标是更加合理的。不管各家接口实现成什么样子,只要能兼容前端框架就是对的。
至此,其实我们可以看到,DOM 接口本身的引入并不存在什么实质性的阻碍。
而且最重要的事,DOM 本身是作为 XXML 的一种补充开发能力所引入的,每个开发者可以根据自己的架构特点选择 XXML 甚至的 DOM 来作为开发方式。
提供 DOM 接口能带来哪些好处?
最后的最后,我们其实要明白,如果要提供 DOM 接口,将会带来那些好处呢?
能够几乎无缝的兼容市面上主流的前端框架,目前测试下来支持的有
VueSvelteReact18。极大的降低开发者的学习和开发成本。可以提供极致的性能优化,做到非常细粒度的组件更新。
和前端主流开发方式对齐,不再分割与割裂,提高开发效率和降低接入成本。
针对三方的跨端框架,可以降低其兼容难度和运行时的体积,提高执行效率。
最关键最关键的是,终于可以抛弃掉 XXML 这套恶心的东西了。没有难用的数据绑定,支持传递函数,不需要考虑 data 内数据是否是视图需要的,自定义组件之间的时序能够得到天然的保障,能够支持 CSS-In-JS 等等。
社区中很多优秀的方案都可以拿来使用,总之,就是优雅,优雅,还是优雅。
全新架构
在理解了上文所讲述的内容之后,就该讲解下我们为了实现上面的功能所做的全新架构了:
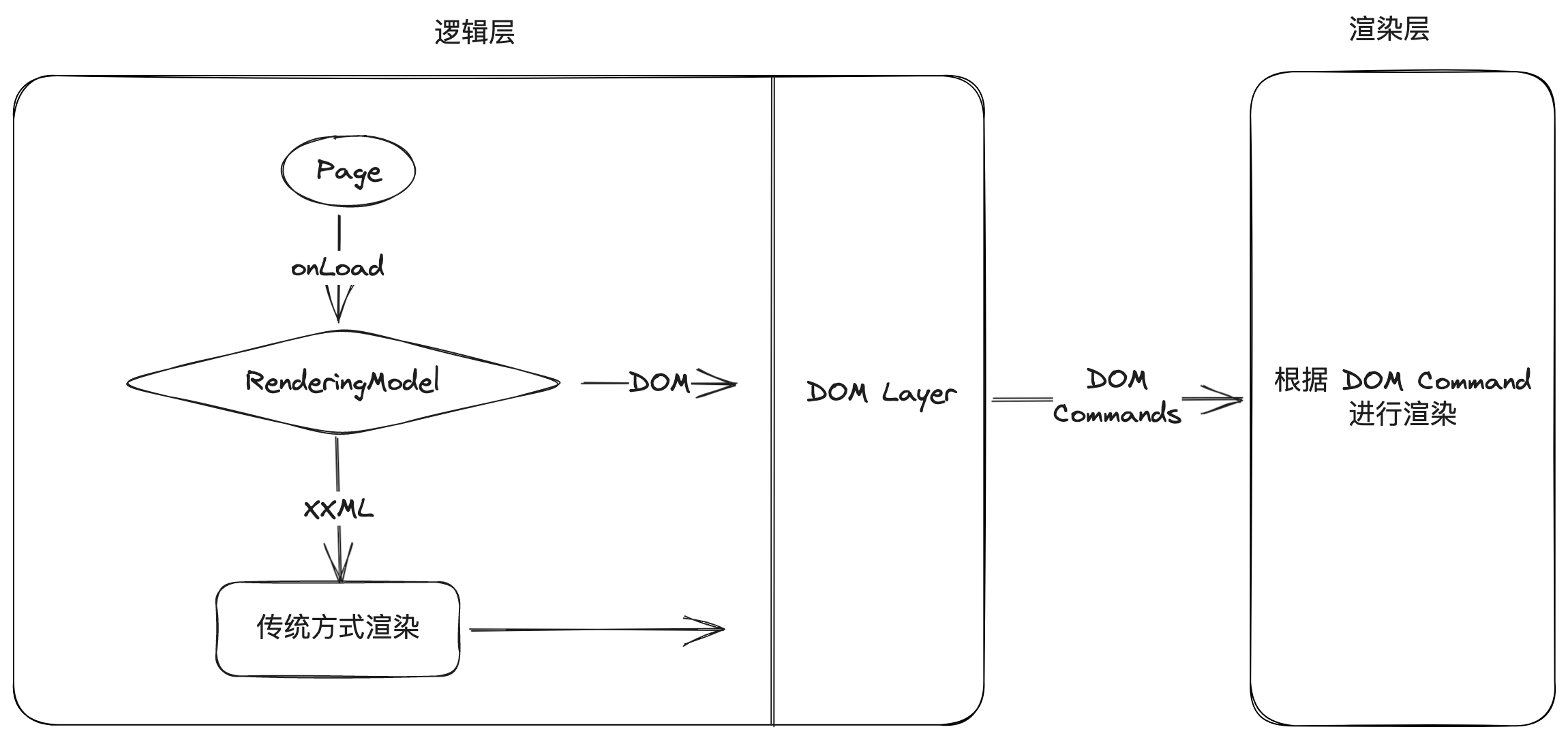
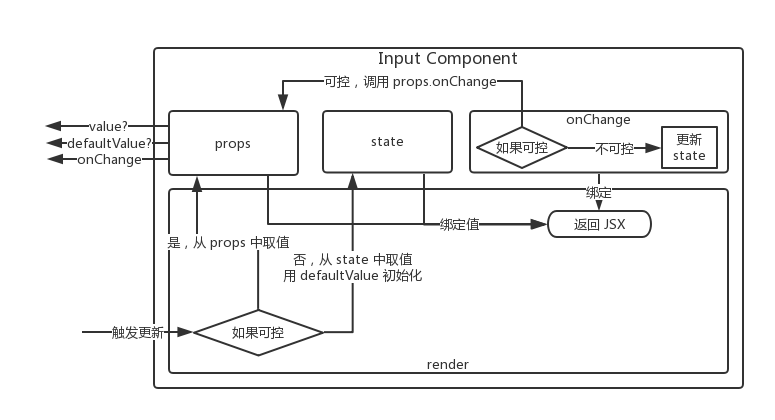
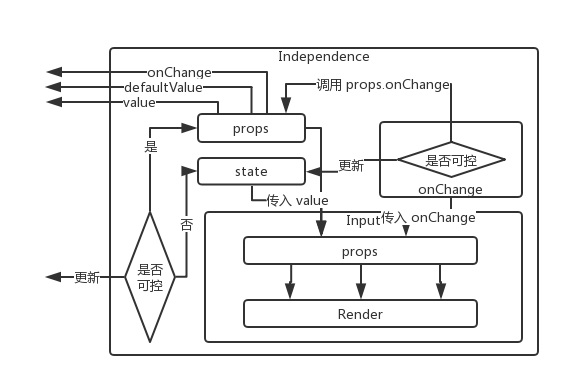
最简单的理解,就是在新架构中,渲染层和逻辑层之间的通讯不再发送 data 了,而是通过逻辑层实现的一套 DOM 接口,将其转换成 DOM 的操作指令。
如果说渲染的操作是 fn(data) 的过程,那么以前这个过程是在渲染层完成,而新架构下,这个操作将在逻辑层完成。
在新架构中,依旧保留了对原先 XXML 的兼容性,开发者可以通过 renderingModel 控制。控制以 Page 为粒度,保证在开发中可以做到渐进式迁移。另外,DOM 接口与 XXML 只能二选一,两者无法在一个 Page 上同时开启。
我并不认为提供 Page 级别的控制在技术设计上是一个好方案,但这个方案确实是可以最大程度上提供更好的兼容性,方便开发者渐进式的替换。
Document 结构
当开启 DOM 的渲染模型之后,整个小程序的文档模型都将与 Web 有着极其类似的结构:
1 | <html> <!-- document.documentElement 一般不会用到这个 --> |
例如每一个 Page 都对应着 document.body 内的一个 <page/> 元素。页面栈也与 document.body.childNodes 保持一致,页面栈的进出相当于 page 元素的插入和剥离。
当然,这里只是一个类比,实际上会有些许的不同,本文不再展开(其实就是我还没设计好,这是个预期模型)。
小程序内置组件
小程序内置组件在 DOM 接口下名字、属性、使用方式依旧保持不变,并且遵守 Web 的通用规范。提供了对应的 DOM Interface 方便开发者直接操作和使用。例如
1 | // tagName 都是和 XXML 内保持一致 |
或许有人会问,为什么使用了 DOM 接口缺不能使用前端的组件呢?
这是因为小程序的组件体系确实是比较特殊的,目前暂时没有很好的办法去兼容。但是在未来,可能会选择开放部分 Web 的组件,例如 div span svg 等。
如何使用
目前该方案还在内部开发阶段,外部没有全量发布。下文中提到的所有接口都属于不稳定接口,在没有正式对外前,只能作为参考。
可能看完上面之后大家依旧会是一头雾水,我这里通过一个简单的 DEMO 来让大家有更加清晰的认识。
- 打开飞书开发者工具中的新框架开关
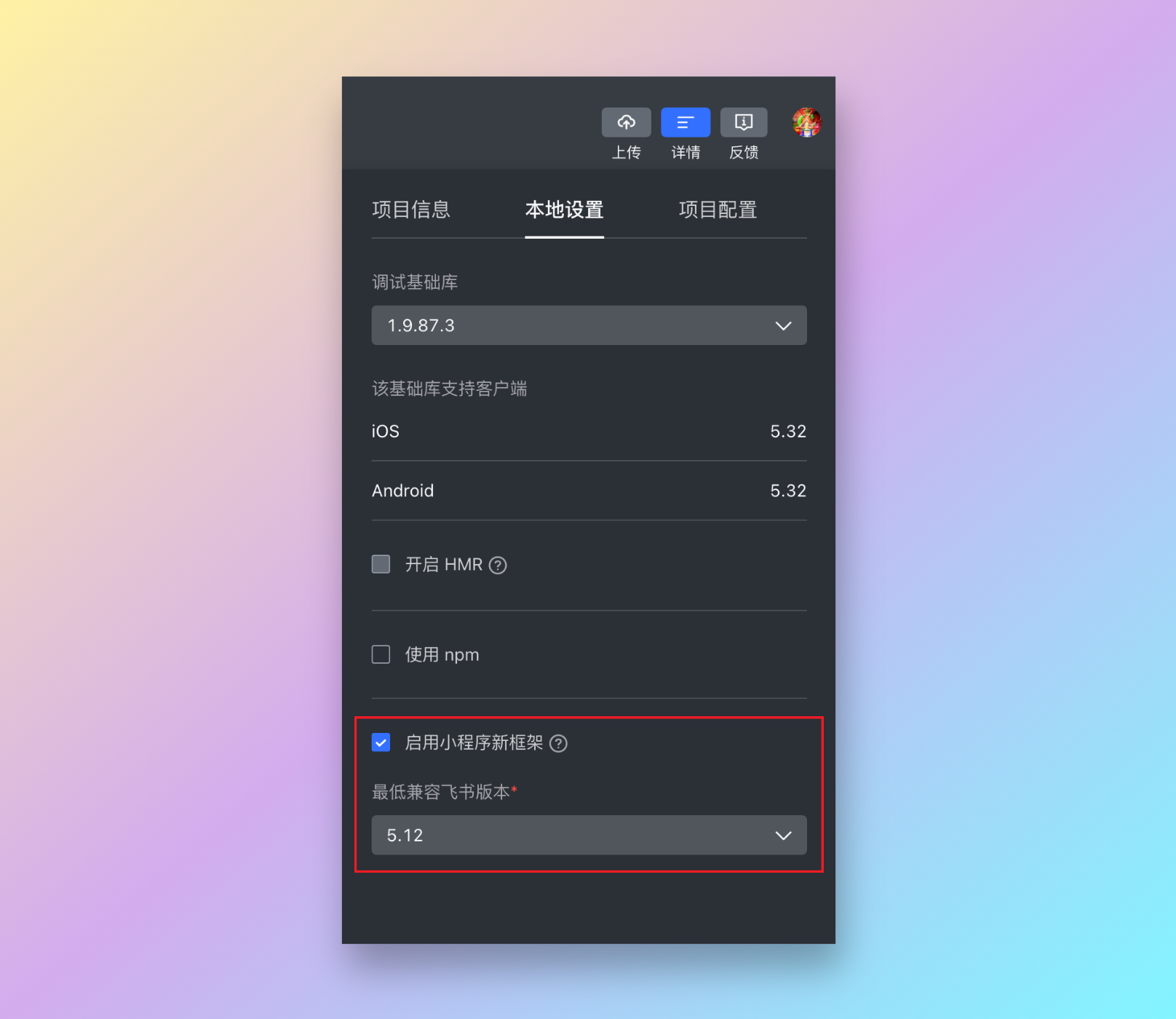
- 在要开启 DOM 接口的 Page 所对应的 JSON 中添加
renderingModel为dom
1 | { |
- 此时可以在 Page 的
onLoad生命周期内通过this.pageElement获取到 Page 的元素实例了,可以将其理解为前端开发中的<div id="app"></div>元素。后续就可以按照前端开发流程去操作这个元素了
1 | Page({ |
- 其他的例如样式、API 等与普通小程序无异。样式依旧通过 XXSS 使用,API 则继续可以使用
tt如果在飞书内的话。
性能对比
性能自然是为什么要引入 DOM 最重要的一个因素了,让我们来看一下性能对比测试
测试方式
仓库:https://github.com/XGHeaven/perf-gadget-dom-vs-framework
使用 Vue3 的框架,Demo 使用 mdn/todo-vue,在此基础上使用了 Taro 将代码分别编译到飞书、微信、支付宝。
taro-wxTaro 编译到微信,微信版本为8.0.35taro-alipayTaro 编译到支付宝,开启 2.0 lib,支付宝版本为10.3.80taro-ttTaro 编译到抖音(Tiktok),抖音版本为25.5.0taro-larkTaro 编译到飞书,飞书版本为6.5.3dom-larkVue 源码直接编译到飞书新架构 DOM 接口上,飞书版本为6.5.3
每一个测试项目,有 5 次的预热运行,之后会再运行 10 次,取其平均值。同时每次运行之间都会相隔一段时间,保证系统有时机去做别的事情,从而尽可能避免影响到测试结果。
之所以选择 Taro 而非 XXML 原生写法或者其他跨端框架,其一是因为更加接近于开发者的使用体验,因为不可能有人会选择直接去操作 DOM。其二是因为 Taro 已经是最快的跨端框架了,再比较其他的没有什么太多的意义。
除此以外,其他的内容基本一致:
测试设备为华为 P40 Pro,麒麟 990 处理器,鸿蒙 OS 3.0 系统。
Taro 框架统一经过 build:xx 命令后运行,Vue 直接通过 Vite 编译后运行
运行方式都是打开对应平台的开发者工具并上传之后,在后台生成对应的二维码扫码预览,避免被认为是开发状态从而添加对结果有影响的能力。
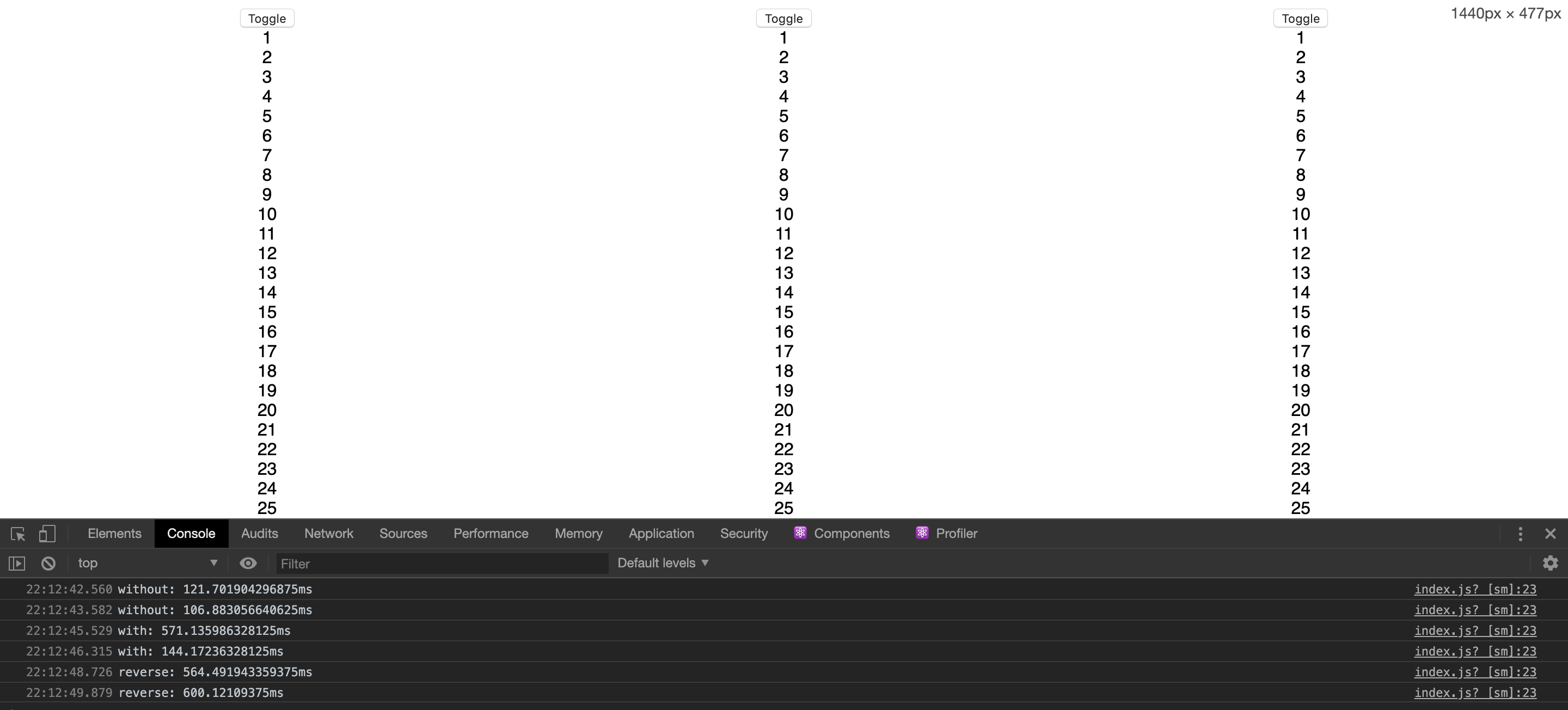
由于 Taro 框架以及飞书新架构的情况下,组件的 mounted 生命周期只能保证在逻辑层侧完成了渲染,不能保证此时组件更新指令已经发送到渲染层,我们需要寻找一个全新的方式去衡量什么时候组件真正渲染上屏。
幸运的是,image 组件有一个特性,当图片被渲染出来并成功加载之后,会触发 load 事件,当此事件触发的时候,可以认为组件已经正确被渲染到屏幕上了。此时,我们只需要在某次更新组件的最后一个组件内,插入一个高宽为 0 的 image 组件作为渲染标记,当事件被触发时,就可以测量出整体的渲染时间。
虽然图片加载会占用一定的时间,但资源本身就是离线保存在代码包内,加载速度很快,且这并不影响最终结果的相对大小。
Taro 默认关闭资源内联功能,避免 Taro 将小资源文件内联成 base64 字符串从而增大通讯成本。
测试内容
这里还需要再补充几点:
不测试应用首屏的性能,由于首屏开始的时间点不同宿主下测量会是不一样的,所以我只在私下里在飞书上通过录屏测试过 Uniapp 对比 DOM,差不多 DOM 可以快 300ms。如果采用 Taro 理论上差距会缩小,但是依旧是快的。
而且首屏性能主要由 JS Parse 和 Execution 的时间组成,这两部分分别由包体积和渲染性能决定,可以分别对比这两项测试从而大体可以得出首屏的性能。
不包含纯静态内容,因为测试使用的是 Taro 框架,其会在逻辑层搞一套虚拟 DOM,会导致最终发送给渲染层的数据量其实基本一致,测试的意义不大。如果有需要,后续可以对比 DOM 和 XXML 的在纯静态内容上的速度差异。
列表组件渲染
渲染 100 个 Todo 项,记录对应的耗时
mounted 耗时,指从组件 created 到 mounted 所花费的时间
完整渲染耗时,指从组件 created 到渲染层上屏渲染完毕(图片 onload 触发)所花费的时间
| 目标 | mounted 耗时 | 完整渲染耗时 |
|---|---|---|
| taro-wx | 141.3 (156%) | 1457.4 (443%) |
| taro-alipay | 141.1 (156%) | 387.2 (177%) |
| taro-tt | 148.5 (165%) | 608.7 (185%) |
| taro-lark | 140.8 (156%) | 620.6 (188%) |
| dom-lark | 89.9 (100%) | 328.9 (100%) |
列表组件内部更新
将 Todo 项内的每一个 checked 进行反转,记录耗时
| 目标 | 完整渲染耗时 |
|---|---|
| taro-wx | 1374.5 (2220%) |
| taro-alipay | 138.7 (224%) |
| taro-tt | 205.3 (331%) |
| taro-lark | 231.7 (374%) |
| dom-lark | 61.9 (100%) |
体积比较
核心逻辑,只包含样式、JS、XXML、SJS 的大小,不包含图片文件,json 等
整包大小,包含图片资源、JS、CSS等整个包的大小
| 目标 | 核心逻辑 | 整包大小 |
|---|---|---|
| taro-wx | 308K (452%) | 336K (323%) |
| taro-alipay | 256K (376%) | 276K (265%) |
| taro-tt | 248K (364%) | 272K (261%) |
| taro-lark | 248K (364%) | 272K (261%) |
| dom-lark | 68K (100%) | 104K (100%) |
测试解读
微信不知为何,性能表现非常差,我也不再倾向于继续和它进行对比,否则数据会非常夸张。
采用 DOM 接口的开发方式,可以简化掉繁重的 Taro runtime 的实现,从而在速度和体积上获取一定的优势。
相比飞书自身,各种情况下速度至少可以提高一倍以上,体积可以降低到原先的 30%。
相比支付宝,体积上依旧保持优势,渲染速度上的优势略低一些,平均不超过 50% 的提升。但这个问题主要是飞书对内置组件(
checkbox、button)实现的性能较差,如果飞书对这部分进行优化后,相信可以获得更好的优势。
新框架会面临那些问题
虽然新架构的 DOM 接口在上面的测试和预期中会带来很多的优势,但这并不意味着一点问题都没有。
新架构虽然保留了对 XXML 的兼容性,但依旧会产生一定的 Break Chagne,具体可以看飞书官方文档。
由于双线程的架构,在逻辑层模拟的那一层 DOM 无法实现任何和渲染结果相关的 API,例如
getComutedStyle。还包括 querySelector 依旧要通过原先的异步方式获取。由于 DOM 接口某些能力实现难度较高,例如
innerHTMLcss parser等,目前与这些相关的能力只有写入没有读取的能力,如果一定要读取,将无法保证一致性。目前样式还不支持动态插入,后续会支持在
<page>或者<head>内动态插入<style>标签来实现。首屏性能。这个上文也说过,后续会有很多办法去优化和实现的,但优先级不高
对我来说,我觉得整体瑕不掩瑜,未来可期。
未来规划与设计
目前新框架能力的开启和 DOM 接口的使用还在内测状态,对外的时间暂时无法确定
未来 DOM 接口还有许多的优化方向,例如如何降低 DOM 指令的数量,降低一些重复字符串的发送等等
由于 DOM 接口在一些非 Web 标准组件中和前端框架有一些冲突,例如 React 无法很好的支持
picker这类需要针对某些属性设置一个对象的情况。后续会推出一些兼容手段去解决这些问题。主流的前端组件组(例如 antd/element/ud)都无法很好的运行在这个上面。一方面是因为这些组件库多多少少都依赖了前端的一些接口,而小程序没有;另一方面,组件库使用的也都是 Web 的标签元素,而不是小程序的组件。后续会尝试推出一定的解决方案去处理这个问题,能够让社区做较少的修改就可以兼容。
会考虑以飞书官方的身份推出一套适配于 DOM 接口的主流前端组件库,根据情况会选择是否需要添加 WebComponent 能力的支持。
未来飞书小程序的规划都是尽可能的向前端标准实现,未来可能会逐渐添加例如
fetchnavigator在内的 BOM 接口能力支持。
为什么要写这篇文章
希望能促进小程序的前进。
小程序业务上的成功并不是其可以恶心开发者的理由,也不应该放弃对其优化的决心。我希望我这一篇有点颠覆传统小程序风格的优化文章,能够探索更多的思路和想法。寻求合作。
由于 DOM 接口的特性,需要更多社区的配合才能将这个发挥到极致,例如 Taro/Uniapp 等三方框架,Vant 等小程序原生组件库等等。沟通交流,拓展思路。
希望能够得到更多人对这件事情的想法和思路,也希望能够得到更多的输入。