作为一个喜欢折腾的人,个人搞了很多东西放在自己的服务器上,但是为了方便,能够在世界各地随时随地的打开查看和使用,我将服务器暴露到了公网中,当然了有些在公有云上的本来就暴露出来的。
那么这里就有一个问题,我如何保护我的信息只能我来查看呢?
最简单的方法就是通过 HTTP Basic Auth + HTTPS。记住一定要上 https,否则你的密码也是会泄漏的。为什么说简单呢?因为只需要在 Nginx 或 Traefik 上配置下就可以了。但是这个方案有一个非常麻烦的问题,就是过一段时间之后就要输入用户名和密码。时间短了,到无所谓,时间一长就会觉得很烦。
构建一套 token 验证体系,不管是使用 oauth 也好还是 jwt 也好,都是可以的。安全性也是可以保证的,而且设置好 token 的时间长度,也能保证避免频繁的输入密码。但是这有一个问题就是实现起来太过于复杂,都快赶上公司的一套系统了。而且还要有各种登录页面,想想都烦。
与上面类似,不过验证方式使用 Two Auth,也就是基于时间的 6 位数组。但是依旧比较复杂。
使用 OpenVPN 的方式。这在一定程度上也能使用,但是对于我来说,OpenVPN 的限制还是比较大的。首先安卓手机无法开启两个 VPN,而且我也不能一直连着 VPN,因为我会部署一些经常用的服务。而且我不是为了能够连接到内网,而是想对外网使用的服务添加验证。
我想了许久,有没有一种不需要输入密码,就可以验证安全的呢?因为是我一个人使用的,所以我根本不需要多用户系统,也就是说验证方式只需要一个密码就可以了。这我突然想起了之前在写 gRPC 的时候有一个双向验证的参数,也可以验证客户端可以不可以。当时觉得只是他们基于 h2 改的协议,结果我一查发现这原来就包含在 https 里面,准确说是 SSL 规范里面。(怪自己当初上计算机网络的时候没好好学这部分,竟然连这个都不知道)
那么至此,思路就很清晰了,给我的所有个人服务都添加 https 客户端校验。只要我的证书够安全,我的页面就是安全的(反正都是我个人的东西,直接拿着 U 盘到处拷贝,手机 Pad 用数据线发送,我就不信这样谁还能盗走我的证书,傲娇脸)
关于 SSL 证书的一些知识
生成证书我们主要采用
openssl具体的安装教程我就不讲解了,有兴趣的小伙伴自行查阅,主要有下面几个步骤:openssl genrsa:生成 Private Key,用于生成请求文件使用,这里用.key后缀。openssl req:依赖上面生成的 Key 去生成 CSR,也就是证书请求文件。使用.csr后缀。这期间要填写一些信息,前面的几个大写字母是缩写,后面在命令行使用的时候会用到。C(Country) 国家
ST(State/Province) 州或者省
L(Locality) 地区,国内写区即可
O(Organization) 组织
OU(Organization) 组织单位
CN(Common Name) 通用名,这个是非常重要的,影响了证书的显示名称和 HTTPS 的域名。
openssl x509:根据 x509 规范,利用 CA 的证书和私钥将 CSR 文件加密成真正可以使用到的证书。使用.crt后缀
SSL 证书必须要采用 sha-2 加密算法。2015 年 12 月 31 日前,CA 机构还会颁发 SHA-1 签名的证书,但是之后只会签发 SHA-2 签名的证书了。Chrome 也会对 SHA-1 签名的证书提示不安全。在 openssl 中用的是
-sha-256参数。CRT和PEM的关系,大家可以简单的认为PEM是将证书 base64 之后的文件,而CRT是既能 base64 也能 binary 的一种文件格式。但是通常openssl产出的是 base64 的文件,你可以通过-outform参数控制产出的类型。
CA 的生成
有了 CA 我们才能去给其他的证书签名,生成 CA 的过程很简单
创建根钥
💡 这个秘钥非常重要,任何获得了这个秘钥的人在知道密码的情况下都可以生成证书。所以请小心保存
1 | openssl genrsa -des3 -out root.key 4096 |
-des3标明了私钥的加密方式,也就是带有密码。建议添加密码保护,这样即使私钥被窃取了,依旧无法对其他证书签名。你也可以更换其他的加密方式,具体的请自行 help。4096表示秘钥的长度。
创建自签名证书
因为是 CA 证书,所以没法让别人去签名,只能自签名。这里可以认为是生成 CSR 和签名两部合成一步走。
1 | openssl req -x509 -sha256 -new -key root.key -sha256 -days 1024 -out root.crt |
服务端证书生成
生成证书私钥
1 | openssl genrsa -out your-domain.com.key 2048 |
和 CA 证书不同,这个私钥一般不需要加密,长度也可以短一些。
生成证书请求文件
1 | openssl req -new -key your-domain.com.key -out your-domain.com.csr |
这期间要填入一些信息,注意 CN 的名字一定要是你的域名。
使用 CA 对 CSR 签名
在 Chrome 58 之前,Chrome 会根据 CN 来检查访问的域名是不是和证书的域名一致,但是在 Chrome 58 之后,改为使用 SAN(Subject Alternative Name) 而不是 CN 检查域名的一致性。
而 SAN 属于 x509 扩展里面的内容,所以我们需要通过 -extfile 参数来指定存放扩展内容的文件。
所以我们需要额外创建一个 your-domain.com.ext 文件用来保存 SAN 信息,通过指定多个 DNS 从而可以实现多域名证书。
1 | subjectAltName = @alt_names |
以此类推,如果域名较少,还可以用另外一种简写方案。
1 | subjectAltName = DNS: your-domain.com, DNS: *.your-domain.com |
关于语法的更多内容请查看官方文档。在有了 ext 文件之后就直接可以开始签名了。
1 | openssl x509 -req -sha256 -in your-domain.com.csr -CA root.crt -CAkey root.key -CAcreateserial -out your-domain.com.crt -days 365 -extfile your-domain.com.ext |
CAcreateserial 这个参数是比较有意思的,意思是如果证书没有 serial number 就创建一个,因为我们是签名,所以肯定会创建一个。序列号在这里的作用就是唯一标识一个证书,当有两个证书的时候,只有给这两个证书签名的 CA 和序列号都一样的情况下,我们才认为这两个证书是一致的。除了自定生成,还可以通过 -set_serial 手动指定一个序列号。
当使用 -CAcreateserial 参数之后,会自动创建一个和 CA 文件名相同的,但是后缀是 .srl 的文件。这里存储了上一次生成的序列号,每次调用的时候都会读取并 +1 。也就是说每一次生成的证书的序列号都比上一次的加了一。
现在,只需要将 your-domain.com.crt 和 your-domain.com.key 放到服务端就可以使用了。别忘了将 CA 添加系统当中,要不然浏览器访问会出现问题。
客户端证书生成
服务端有了之后,就需要生成客户端的证书,步骤和服务端基本一致,但是不需要 SAN 信息了。
1 | openssl genrsa -out client.key 2048 |
只不过客户端验证需要的是 PKCS#12 格式,这种格式是将证书和私钥打包在了一起。因为系统需要知道一个证书的私钥和公钥,而证书只包含公钥和签名,不包含私钥,所以需要这种格式的温江将私钥和公钥都包含进来。
1 | openssl pkcs12 -export -clcerts -in client.crt -inkey client.key -out client.p12 |
这期间会提示你输入密码,用于安装的时候使用。也就是说不是什么人都可以安装客户端证书的,要有密码才行,这无疑又增加了一定的安全性。当然了,我试过不输入密码,但是好像有点问题,有兴趣的同学可以自己尝试下。
客户端校验证书的使用
这里以 Node.js 举例。使用 https 模块,在创建的时候和普通的创建方式基本一致,但是需要额外指定 requestCert 和 ca 参数来开启客户端校验。
1 | https.createServer({ |
这样只要客户端没有安装合法的证书,那么整个请求就是失败的。而且根本不会进入请求处理的回调函数中,这也意味着显示的错误是浏览器的默认错误。那么这对用户来讲其实不太友好。
那么我们可以通过在参数中添加 rejectUnauthorized: false 来关闭这个功能,也就是说不管客户端证书校验是正确还是失败,都可以进入正常的回调流程。此时我们只需要通过 req.client.authorized 来判断这个请求是否通过了客户端证书的校验,可以给予用户更详尽的错误提示。
另外我们还可以通过 resp.connection.getPeerCertificate() 获取客户端证书的信息,甚至可以根据不同的信息选择给予不同的用户权限。
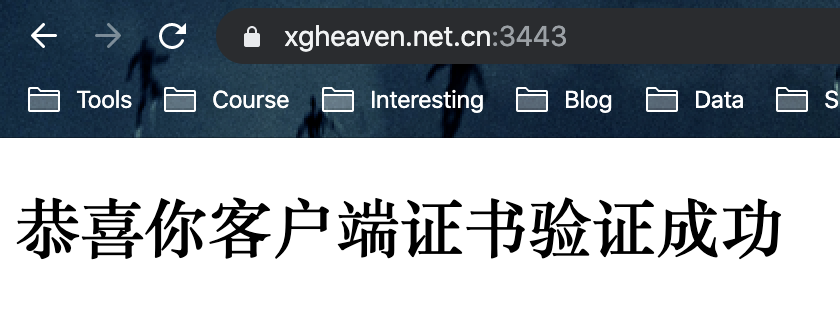
这里有一个 DEMO: https://www.xgheaven.net.cn:3443,大家打开之后应该会看到一个证书校验失败的提示。这里要说下,我这里的 DEMO 没有使用自签名的服务端证书,只是使用了自签名的 CA 去检查客户端证书。因为用自己签名的服务端证书的话,浏览器会提示不安全,因为用户么有安装自签名的 CA。
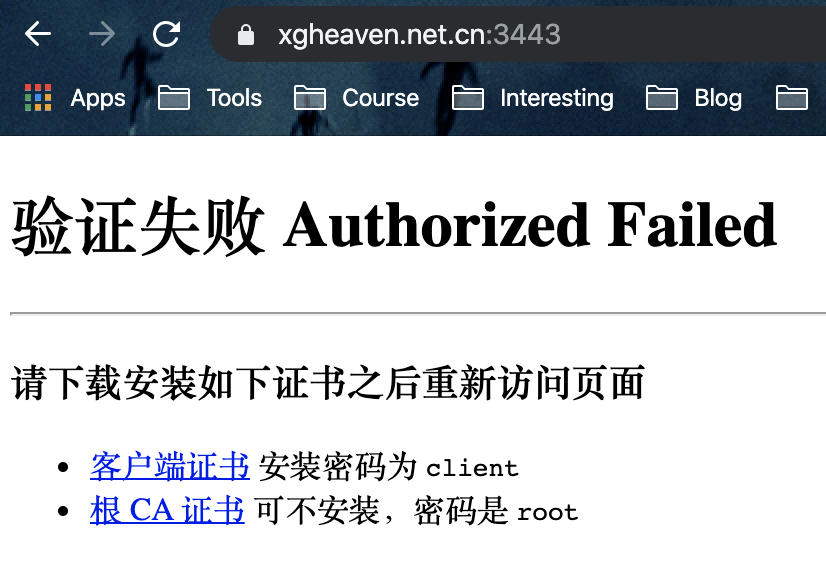
可以点击下载客户端证书按钮,安装客户端证书。因为客户端证书是有密码保护的,请输入页面上提示的密码。
再次刷新,如果是 Mac 系统,会提示你要使用哪个客户端证书登录,此时就说明安装成功了。
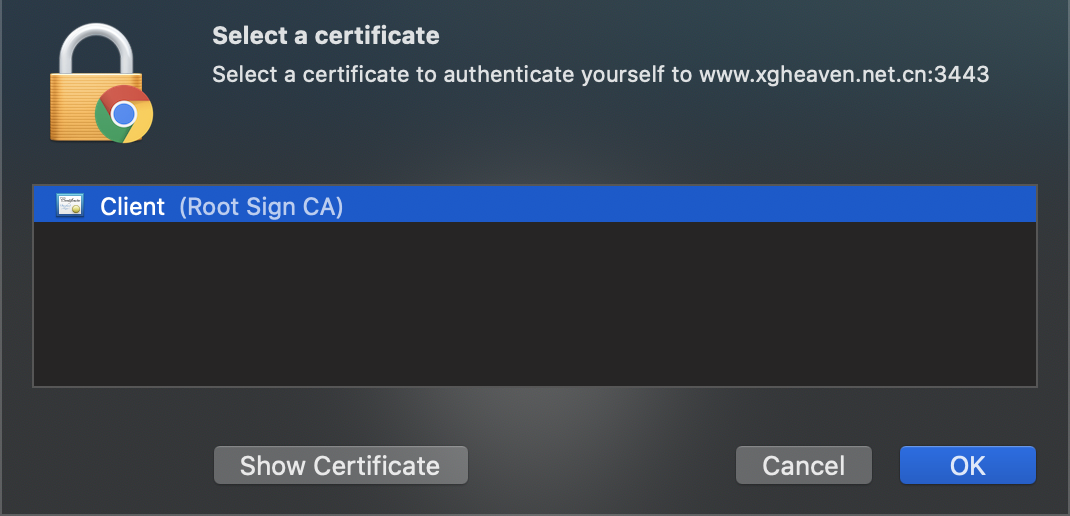
点击确认,可能还要输入一个系统密码允许 Chrome 访问 Keychain,一劳永逸的话在输入密码之后选择 Always Allow,从此就不需要再输入密码了。
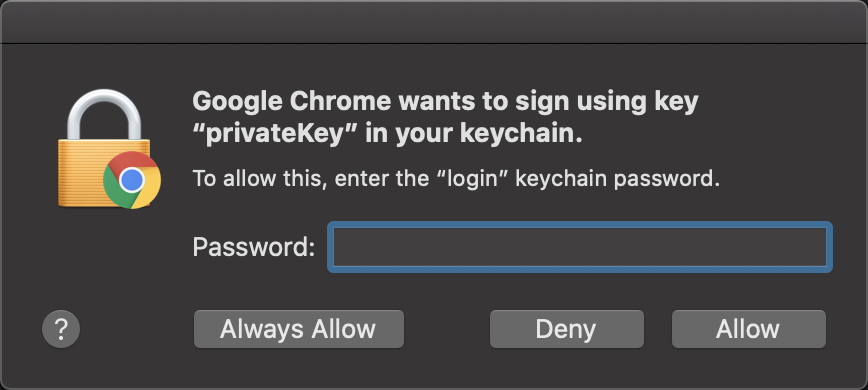
按照道理,你就可以看到这个页面了。
结语
有了这个功能,我就可以将我的所有内容全盘私有化而且还能直接暴露在公网中。配合之前毕设搞的微服务化,简直不要美滋滋。如果之前是使用账号密码登录的,也可以接入这个方案。就是将登录页面替换成证书校验就可以了。