目录
前言:本人入职之后算是第一次真正去写 React,发现了 React 的组件系统和其他框架的组件系统有些许的不同,这也触发了我对其中组件的可控性的一些思考和总结。
自从前端有了组件系统之后,有一个很常见但是却又被大家忽视的概念,就是可控组件(Controlled Component)和不可控组件(Uncontrolled Component)。
什么是可控和不可控?
官方详细讲解了什么事可控和不可控组件,虽然只是针对 input 组件的 value 属性来讲的。但是对于很多第三方组件库来讲,一个组件不止有一个数据属于可控。比如 Ant Design 的 Select 组件,value 和 open 都属于可控的数据,如果你让 value 可控 open 不可控,那这到底是可控组件还是不可控组件呢?
所以从广义来讲使用可控/不可控组件其实不是很恰当,这里使用可控数据与不可控数据更加合理一点。一个组件可能可能同时有可控的数据和不可控的数据。
可控数据是指组件的数据被使用者所控制。不可控数据是指组件的数据不由使用者来控制而是由组件内部控制。
之所以会有可控和不可控,主要是跟人奇怪的心理有关。如果把框架比作一个公司,组件比作人,组件之间的关系比作上下级。那么上级对下级的期望就是你既能自己做好分内的事情,也可以随时听从我的命令。这本身就是一件矛盾的事情,一边撒手不管,一边又想全权掌控。遇到这样的上级,下级肯定会疯了吧。
为啥要区分呢?
在 Vue 中,其实都忽视了这两者的区别,我们来看下面这个例子。
1 | <input/> |
上面是一个最简单 Input 组件,我们来思考一下如下几种使用场景:
如果我只关心最后的结果,也就是输入的值,中间的过程不关心,最简单的方式是用
v-model或者自己在change事件里面获取值并保存下来。
这种场景是非常普遍,Vue 可以很好的完成,结果也符合人们的预期。1
2
3<input v-model="value"/>
<!-- OR -->
<input @change="change"/>如果我也只是关心结果,但是想要一个初始值。 也很简单,通过 value 传入一个静态字符串不就好了,或者传入一个变量,因为 Vue 的 props 是单向的。
其中第三个方案并不是非常正确的方式,如果initValue在用户输入期间发生了更新,那么他将覆盖用户的数据,且不会触发change事件。1
2
3<input v-model="value"/> <!-- value 有初始值 -->
<input value="init string" @change="change"/>
<input :value="initValue" @change="change"/>我不仅仅关心结果,还关心过程,我需要对过程进行控制。比如说把输入的字符串全部大小写,或者锁定某些字符串。 熟练的工程师肯定可以写出下面的代码。
但是这会有问题:1
2<input v-model="value"/> <!-- watch "value",做修改 -->
<input :value="value" @change="change"/> <!-- 在 change 中修改数据 -->数据的修改都是在渲染 dom 之后,也就是说你不管怎么处理,都会出现输入的抖动。
如果通过第二种方法,恰巧你做的工作是限制字符串长度,那么你这样写
change(e) {this.value = e.target.slice(0, 10)}函数会发现没有效果。这是因为当超过 10 字符之后,value 的值长度一直是 10,vue 没有检测到 value 的变化,从而不会更新 input.value。
出现这个问题最关键的是因为没有很好的区分可控组件和不可控组件,我们来回顾一下上面的某一段代码:
1 | <input :value="value" @change="change"/> |
你能从这块代码能看出来使用这个组件的用户的意图是什么呢?他是想可控的使用组件还是说只是想设置一个初始值?你无法得知。我们人类都无法得知,那么代码层面就不可能得知的了。所以 vue 对这一块的处理其实是睁一只眼闭一只眼。用户用起来方便,
用一个例子来简单描述一下:上级让你去做一项任务,你询问了上级关于这些任务的信息(props),然后你就开始(初始化组件)工作了,并且你隔一段时间就会向上级汇报你的工作进度(onChange),上级根据你反馈的进度,合理安排其他的事情。看起来一切都很完美。但是有的上级会有比较强的控制欲,当你提交了你的工作进度之后,他还会瞎改你的工作,然后告诉你,按照我的继续做。然后下级就懵逼,当初没说好我要接受你的修改的呀(value props),我这里也有一份工作进度呀(component state),我应该用我自己的还是你的?
对于人来说,如何处理上级的要求(props)和自身工作(state)是一个人情商的表现,这个逻辑很符合普通人的想法,但是对于计算机来说,它没有情商也无法判断究竟应该听谁的。为了克服这个问题,你需要多很多的判断和处理才可以,而且对于一些不变的值,你需要先清空再 nextTick 之后赋值才可以出发组件内部的更新。
最近入职之后,公司用到了 React,我才真正的对这个有所理解。
value? defaultValue? onChange?
如果对 React 可控组件和不可控组件有了解了可以跳过这块内容了。
让我们来看一下 React 如何处理这个的?我们还是拿上面的那三种情况来说:
如果我只关心最后的结果,也就是输入的值,中间的过程不关心
1
<input onChange={onChange}/>
如果我也只是关心结果,但是想要一个初始值
1
2<input defaultValue="init value" onChange={onChange}/>
<input defaultValue={initValue} onChange={onChange}/>我不仅仅关心结果,还关心过程,我需要对过程进行控制
1
<input value={value} onChange={onChange}/>
当看完了这段你会很清楚的知道什么样的结构是可控,什么结构是不可控:
如果有
value那么就属于可控数据,永远使用value的值否则属于不可控数据,由组件使用内部
value的值,并且通过defaultValue设置默认值
不论什么情况修改都会触发 onChange 事件。
React 对可控和不可控的区分其实对于计算机来说是非常合理的,而且也会让整个流程变的非常清晰。当然,不仅仅只有这一种设置的方式,你可以按照一定的规则也同样可以区分,但是保证可控和不可控之间清晰的界限是一个好的设计所必须要满足的。
propName in this.props?
了解上面的概念之后,我们进入到实战环节,我们怎么从代码的层面来判断当前组件是可控还是不可控呢?
根据上面的判断逻辑来讲:
1 | const isControlled1 = 'value' in this.props // approval 1 |
我们来观察上面几个判断的方式,分别对应一下下面几个模板(针对第三方组件):
1 | <Input value={inputValue} /> // element 1,期望可控 |
可以得到如下表格
| 是否可控 | approval 1 | approval 2 | approval 3 |
|---|---|---|---|
| element1 | true |
true |
true |
| element2 | true |
false |
true |
| element3 | false |
false |
false |
| element4 | true |
false |
false |
大家第一眼就应该能看出来方法二其实是不正确的,他无法很好的区分这两种状态,所以直接 pass 掉。
眼尖的同学也会发现为什么 element 4 的期望没有填写呢?这是因为有一条官方的规则没有讲,这条规则是这样的:当设置了 **value** 属性之后,组件就变成了可控组件,会阻止用户修改 input 的内容。但是如果你想在设置了 **value** prop 的同时还想让用户可以编辑的话,只可以通过设置 **value** 为 **undefined** 或 **null**。
在官方的这种规则下面,element 4 期望是不可控组件,也就是说 approval 3 是完全符合官方的定义的。但是这样会导致可控和不可控之间的界限有些模糊。
1 | <Input value={inputValue} /> |
所以这里其实我推荐使用 approval 1 的方式,这也是 antd 所采用的。虽然不符合官方的定义,但是我觉得符合人们使用组件的一种直觉。第六感,=逃=
Independence
有了判断的方法,那么我们可以画出一个简单的流程图(Input 组件为例):
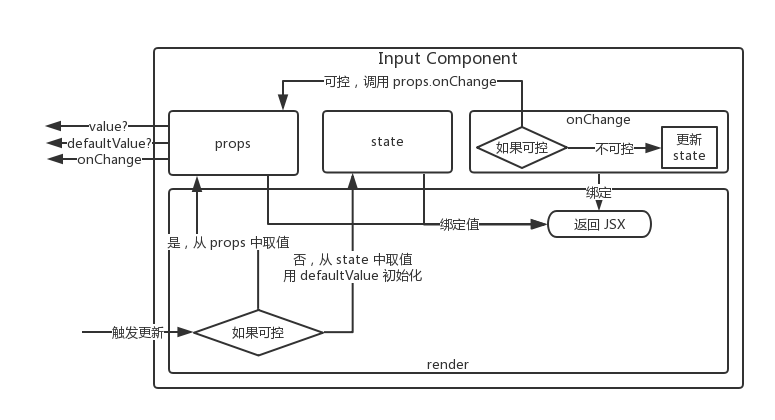
图片有点复杂,简单来讲就是每一次需要获取可控数据或者更新可控数据的时候,都需要检测一下当前组件的状态,并根据状态选择是从 props 中获取数据还是从 state 中获取数据已经更新的时候调用的是那个函数等等。图中有一些箭头的方向不是很正确,而且部分细节未画出,大家见谅。
如果只是添加这一个可控的属性 value ,这样写未尝不可,但是如果我们要同时考虑很多属性呢?比如说 Antd Select 组件就同时有 value 和 open 两个可控属性,那么整个代码量是以线性方式增长的。这很明显是无法接受的。
于是这里我引入了 Independence 装饰器来做这件事情。架构如下:
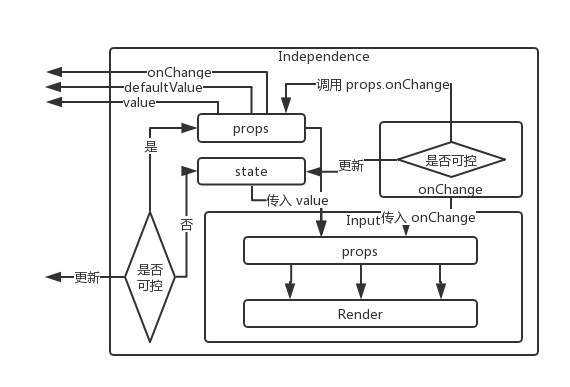
我们可以这么理解,一个支持可控和不可控的组件本质上可以拆分成内部一个展示型的无状态受控的组件和外面的包装组件,通过包装(也就是高阶组件的方式)让内部受控组件支持不可控。
这样写其实有如下几个好处:
组件逻辑复杂度降低,只需要将组件的受控情况
可以将任意受控组件包装成不受控组件,尤其是对第三方组件的封装上
组件复杂度降低,代码冗余变少
非常方便的添加和删除受控属性,只需要修改装饰器即可
如何使用?
目前我简单实现了 Independence 装饰器,代码在网易猛犸开源的组件库 bdms-ui(建设中,组件不全、文档不全、时间不够,敬请期待)中,代码在此。
他遵循这样的规范:假如属性名称为 **value**,那么默认值为 **defaultValue**,change 事件为 **onValueChange**。支持通过 onChangeName 修改 change 事件名称,通过 defaultName 修改默认值名称。
另外最简单的使用方式就是通过装饰器了,拿 Select 组件举例。
1 | @Independence({ |
从此编写可控和不可控的数据从未如此简单。另外 Independence 还实现了 forward ref 的功能。
不过现在功能还比较薄弱,需要经过时间的检验,等完备之后可以封装成一个库。
总结
本文简单讲解了一下什么是可控和不可控,以及提出了一个 React 的解决方案。
这些只是基于我的经验的总结,欢迎大家积极交流。