概要
本文主要讲解了下我平时在工作开发中遇到的关于 Hooks 的一些缺点和问题,并尝试配合 Mobx 解决这些问题的经历。我觉得两者的配合可以极大的降低开发过程中有可能出现的问题以及极大的提高开发体验,而且学习成本也是非常的低。如果你对 Hooks 以及 Mobx 有兴趣,想知道更进一步的了解,那么这篇文章适合你。这篇文章会介绍如下内容,方便你决定是否要仔细阅读,节省时间:
本文不会介绍太过于基础的内容,你需要对 Mobx 以及 Hooks 有基础的了解
本文介绍了平时开发中的一些最佳实践,方便小伙伴们对两者有更加深入的认识
如果你使用过一部分 Mobx,但是不太了解如何和 Hooks 更好的合作,可以尝试来看看
另外 Hooks 本身真的就是一个理解上非常简单的东西,所以本文也不长,我也不喜欢去写什么万字长文,又不是写教程,而且读者看着标题就失去兴趣了。
Hooks 究竟有什么问题?
首先,在这里我不再说 Hooks 的优点,因为他的优点用过的人都清楚是怎么回事,这里主要讲解一下他存在的缺点,以及如何用 Mobx 来进行改进。
依赖传染性 —— 这导致了开发复杂性的提高、可维护性的降低
缓存雪崩 —— 这导致运行性能的降低
异步任务下无法批量更新 —— 这也会导致运行性能的降低
换句话说,造成这种原因主要是因为 Hooks 每次都会创建一个全新的闭包,而闭包内所有的变量其实都是全新的。而每次都会创建闭包数据,而从性能角度来讲,此时缓存就是必要的了。而缓存又会牵扯出一堆问题。
说到底,也就是说没有一个公共的空间来共享数据,这个在 Class 组件中,就是 this,在 Vue3 中,那就是 setup 作用域。而 Hooks 中,除非你愿意写 useRef + ref.current 否则是没有办法找到共享作用域。
而 mobx 和 Hooks 的结合,可以很方便在 Hooks 下提供一个统一的作用域来解决上面遇到的问题,所谓双剑合并,剑走天下。
Hook1 useObserver
在传统的使用 mobx 的过程中,大家应该都知道 observer 这个 api,对需要能够响应式的组件用这个包裹一下。同样,这个 api 直接在 hooks 中依旧可以正常使用。 但是 hooks 并不推荐 hoc 的方式。自然,mobx 也提供了 hookify 的使用方式,那就是 useObserver。
1 | const store = observable({}) |
看到这里,相信使用过 mobx 的应该可以发现,useObserver 的使用几乎和 Class 组件的 render 函数的使用方式一致。事实上也确实如此,而且他的使用规则也很简单,直接把需要返回的 Node 用该 hooks 包裹后再返回就可以了。
经过这样处理的组件,就可以成功监听数据的变化,当数据变化的时候,会触发组件的重渲染。至此,第一个 api 就了解完毕了
Hook2 useLocalStore
简单来讲,就是在 Hooks 的环境下封装的一个更加方便的 observable。就是给他一个函数,该函数返回一个需要响应式的对象。可以简单的这样理解
1 | const store = useLocalStore(() => ({key: 'value'})) |
然后就没有了,极其简单的一个 api 使用。而后面要讲的一些最佳实践更多的也是围绕这个展开,后文简化使用 local store 代指。
这两个 API 能带来什么?
简单来讲,就是在保留 Hooks 的特性的情况下,解决上面 hooks 所带来的问题。
第一点,由于 local store 的存在,作为一个不变的对象存储数据,我们就可以保证不同时刻对同一个函数的引用保持不变,不同时刻都能引用到同一个对象或者数据。不再需要手动添加相关的 deps。由此可以避免 useCallback 和 useRef 的过度使用,也避免很多 hooks 所面临的的闭包的坑(老手请自动忽略)。依赖传递性和缓存雪崩的问题都可以得到解决
直接上代码,主要关注注释部分
1 | // 要实现一个方法,只有当鼠标移动超过多少像素之后,才会触发组件的更新 |
第二,就是针对异步数据的批量更新问题,mobx 的 action 可以很好的解决这个问题
1 | // 组件挂载之后,拉取数据并重新渲染。不考虑报错的情况 |
不过也有人会说,这种情况下用 useReducer 不就好了么?确实,针对这个例子是可以的,但是往往业务中会出现很多复杂情况,比如你在异步回调中要更新本地 store 以及全局 store,那么就算是 useReducer 也要分别调用两次 dispatch ,同样会触发两次渲染。而 mobx 的 action 就不会出现这样的问题。// 如果你强行 ReactDOM.unstable_batchedUpdates 我就不说啥了,勇士受我一拜
Quick Tips
知道了上面的两个 api,就可以开始愉快的使用起来了,只不过这里给大家一下小 tips,帮助大家更好的理解、更好的使用这两个 api。(不想用而且也不敢用「最佳实践」这个词,感觉太绝对,这里面有一些我自己也没有打磨好,只能算是 tips 来帮助大家拓展思路了)
no this
对于 store 内的函数要获取 store 的数据,通常我们会使用 this 获取。比如
1 | const store = useLocalStore(() => ({ |
这种方式一般情况下使用完全没有问题,但是 this 依赖 caller,而且无法很好的使用解构语法,所以这里并不推荐使用 this,而是采用一种 no this 的准则。直接引用自身的变量名
1 | const store = useLocalStore(() => ({ |
避免 this 指向的混乱
避免在使用的时候直接解构从而导致 this 丢失
避免使用箭头函数直接定义 store 的 action,一是没有必要,二是可以将职责划分的更加清晰,那些是 state 那些是 action
source
在某些情况下,我们的 local store 可能需要获取 props 上的一些数据,而通过 source 可以很方便的把 props 也转换成 observable 的对象。
1 | function App(props) { |
当然,这里不仅仅可以用于转换 props,可以将很多非 observable 的数据转化成 observable 的,最常见的比如 Context、State 之类,比如
1 | const context = useContext(SomeContext) |
自定义 observable
有的时候,默认的 observable 的策略可能会有一些性能问题,比如为了不希望针对一些大对象全部响应式。可以通过返回自定义的 observable 来实现。
1 | const store = useLocalStore(() => observable({ |
甚至你觉得自定义程度不够的话,可以直接返回一个自定义的 store
1 | const store = useLocalStore(() => new ComponentStore()) |
类型推导
默认的使用方式下,最方便高效的类型定义就是通过实例推导,而不是通过泛型。这种方式既能兼顾开发效率也能兼顾代码可读性和可维护性。当然了,你想用泛型也是可以的啦
1 | // 使用这种方式,直接通过对象字面量推导出类型 |
但是这个仅仅建议用作 local store 的时候,也就是相关的数据是在本组件内使用。如果自定义 Hooks 话,建议还是使用预定义类型然后泛型的方式,可以提供更好的灵活性。
memo?
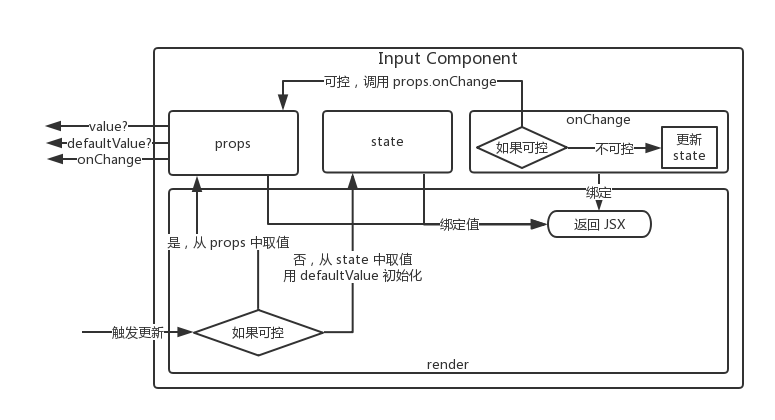
当使用 useObserver api 之后,就意味着失去了 observer 装饰器默认支持的浅比较 props 跳过渲染的能力了,而此时需要我们自己手动配合 memo 来做这部分的优化
另外,memo 的性能远比 observer 的性能要高,因为 memo 并不是一个简单的 hoc
1 | export default memo(function App(){ |
不再建议使用 useCallback/useRef/useMemo 等内置 Hooks
上面的这几个 Hooks 都可以通过 useLocalStore 代替,内置 Hooks 对 Mobx 来说是毫无必要。而且这几个内置 api 的使用也会导致缓存的问题,建议做如下迁移
useCallback 有两种做法
如果函数不需要传递给子组件,那么完全没有缓存的必要,直接删除掉 useCallback 即可,或者放到 local store 中也可以
如果函数需要传递给子组件,直接放到 local store 中即可。
useMemo 直接放到 local store,通过 getter 来使用
useEffect or reaction?
经常使用 useEffect 知道他有一个功能就是监听依赖变化的能力,换句话说就是可以当做 watcher 使用,而 mobx 也有自己的监听变化的能力,那就是 reaction,那么究竟使用哪种方式更好呢?
这边推荐的是,两个都用,哈哈哈,没想到吧。
1 | useEffect(() => |
说正经的,针对非响应式的数据使用 useEffect,而响应式数据优先使用 reaction。当然如果你全程抛弃原生 hooks,那么只用 reaction 也可以的。
组合?拆分?
逻辑拆分和组合,是 Hooks 很大的一个优势,在 mobx 加持的时候,这个有点依旧可以保持。甚至在还更加简单。
1 | function useCustomHooks() { |
App Store
Mobx 本身就提供了作为全局 Store 的能力,这里只说一下和 Hooks 配合的使用姿势
当升级到 mobx-react@6 之后,正式开始支持 hooks,也就是你可以简单的通过这种方式来使用
1 | export function App() { |
Context 永远是数据共享的方案,而不是数据托管的方案,也就是 Store
这句话怎么理解数据共享和组件通讯呢?举个例子
有一些基础的配置信息需要向下传递,比如说 Theme。而子组件通常只需要读取,然后做对应的渲染。换句话说数据的控制权在上层组件,是上层组件共享数据给下层组件,数据流通常是单向的,或者说主要是单向的。这可以说是数据共享
而有一些情况是组件之间需要通讯,比如 A 组件需要修改 B 组件的东西,这种情况下常见的做法就是将公共的数据向上一层存放,也就是托管给上层,但是使用控制权却在下层组件。其实这就是全局 Store,也就是 Redux 这类库做的事情。可以看出来数据流通常是双向的,这就可以算作数据托管
曾经关注过 Hooks 的发展,发现很多人在 Hooks 诞生的时候开始尝试用 Context + useReducer 来替换掉 Redux,我觉得这是对 Context 的某种曲解。
原因就是 Context 的更新问题,如果作为全局 Store,那么一定要在根组件上挂载,而 Context 检查是否发生变化是通过直接比较引用,那么就会造成任意一个组件发生了变化,都会导致从 Provider 开始的整个组件树发生重新渲染的情况。
1 | function App() { |
而如果你想避免这些问题,那就要再度封装一层,这和直接使用 Redux 也就没啥区别了。
主要是 Context 的更新是一个性能消耗比较大的操作,当 Provider 检测到变化的时候,会遍历整颗 Fiber 树,比较检查每一个 Consumer 是否要更新。
专业的事情交给专业的来做,使用 Redux Mobx 可以很好的避免这个问题的出现。
如何写好一个 Store
知道 Redux 的应该清楚他是如何定义一个 Store 吧,官方其实已经给出了比较好的最佳实践,但在生产环境中,使用起来依旧很多问题和麻烦的地方。于是就诞生了很多基于 Redux 二次封装的库,基本都自称简化了相关的 API 的使用和概念,但是这些库其实大大增加了复杂性,引入了什么 namespace/modal 啥的,我也记不清了,反正看到这些就自动劝退了,不喜欢在已经很麻烦的东西上为了简化而做的更加麻烦。
而 Mobx 这边,官方也有了一个很好的最佳实践。我觉得是很有道理,而且是非常易懂易理解的。
但还是那个问题,官方在有些地方还是没有进行太多的约束,而在开发中也遇到了类似的问题,所以这里在基于官方的框架下有几点意见和建议:
保证所有修改 store 的操作都只能在 store 内部操作,也就是说你要通过调用 store 上的 action 方法更新 store,坚决不能在外部直接修改 store 的 property 的值。
保证 store 的可序列化,方便 SSR 的使用以及一些 debug 的功能
类构造函数的第一个参数永远是初始化的数据,并且类型保证和 toJSON 的返回值的类型一致
如果 store 不定义 toJSON 方法,那么要保证 store 中的数据不存在不可序列化的类型,比如函数、DOM、Promise 等等类型。因为不定义默认就走 JSON.stringify 的内置逻辑了
store 之间的沟通通过构造函数传递实现,比如 ThemeStore 依赖 GlobalStore,那么只需要在 ThemeStore 的构造参数中传入 GlobalStore 的实例即可。不过说到这里,有的人应该会想到,这不就是手动版本的 DI 么。没错,DI 是一个很好的设计模式,但是在前端用的比较轻,就没必要引入库来管理了,手动管理下就好了。也通过这种模式,可以很方便的实现 Redux 那种 namespace 的概念以及子 store
如果你使用 ts 开发,那么建议将实现和定义分开,也就是说分别定义一个 interface 和 class,class 继承 Interface,这样对外也就是组件内只需要暴露 interface 即可。这样可以很方便的隐藏一些你不想对外部暴露的方法,但内部却依旧要使用的方法。还是上面的例子,比如 GlobalStore 有一个属性是 ThemeStore 需要获取的,而不希望组件获取,那么就可以将方法定义到 class 上而非 interface 上,这样既能有良好的类型检查,又可以保证一定的隔离性。
是的,基本上这样就可以写好一个 Store 了,没有什么花里胡哨的概念,也没有什么乱七八糟的工具,约定俗成就足以。我向来推崇没有规则就是最大的规则,没有约束就是最大的约束。很多东西能约定俗成就约定俗成,落到纸面上就足够了。完全没必要做一堆 lint/tools/library 去约束,既增加了前期开发成本,又增加了后期维护成本,就问问你司内部有多少 dead 的工具和库?
俗话说的话,「秦人不暇自哀而后人哀之,后人哀之而不鉴之,亦使后人而复哀后人也」,这就是现状(一巴掌打醒)
不过以上的前提是要求你们的开发团队有足够的开发能力,否则新手很多或者同步约定成本高的话,搞个库去约束到也不是不行(滑稽脸)
缺点?
说了这么多,也不是说是万能的,有这个几个缺点
针对一些就带状态的小组件,性能上还不如原生 hooks。可以根据业务情况酌情针对组件使用原生 hooks 还是 mobx hooks。而且针对小组件,代码量可能相应还是增多。因为每次都要包裹
useObserver方法。mobx 就目前来看,无法很好在未来使用异步渲染的功能,虽然我觉得这个功能意义不大。某种程度上说就是一个障眼法,不过这个思路是值得一试的。
需要有一定 mobx 的使用基础,如果新手直接上来写,虽然能避免很多 hooks 的坑,但是可能会踩到不少 mobx 坑
总结
Mobx 在我司的项目中已经使用了很久了,但 Hooks 也是刚刚使用没多久,希望这个能给大家帮助。也欢迎大家把遇到的问题一起说出来,大家一起找解决办法。
我始终觉得基于 Mutable 的开发方式永远是易于理解、上手难度最低的方式,而 Immutable 的开发方式是易维护、比较稳定的方式。这两者没必要非此即彼,而 Mobx + React 可以认为很好的将两者整合在一起,在需要性能的地方可以采用 Immutable 的方式,而在不需要性能的地方,可以用 Mutable 的方式快速开发。
当然了,你就算不用 Mobx 也完全没有问题,毕竟原生的 Hooks 的坑踩多了之后,习惯了也没啥问题,一些小项目,我也会只用原生 Hooks 的(防杠声明)。